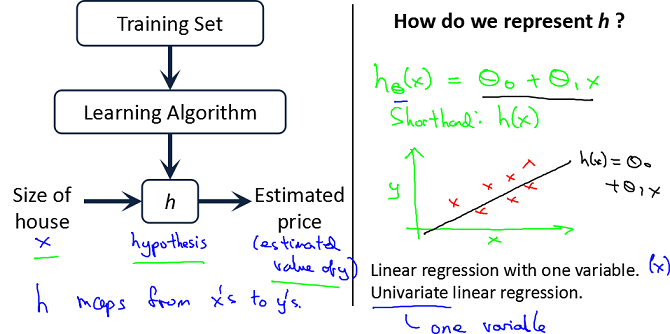
Model representation
Notation:
- m = Number of training examples
- x’s = “input” variable/features
- y’s = “output” variables/”target” variable
- (x,y) = one training example
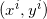 = ith training example
= ith training example- h = hypothesis
Cost function
- Hypothesis:
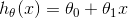
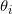 :Parameters , but how to choose ?
:Parameters , but how to choose ?- Minimize modeling error:

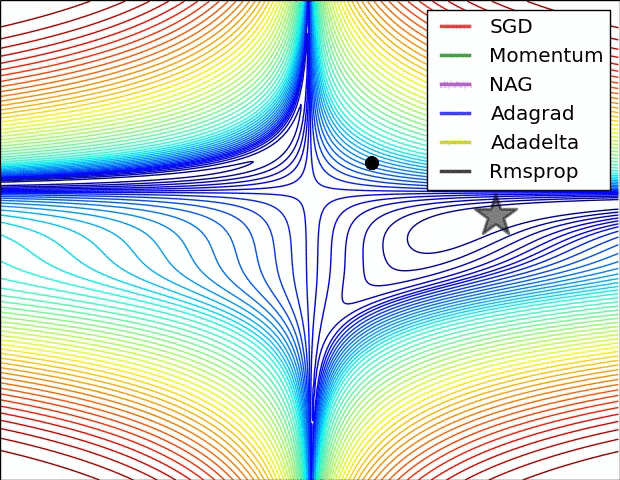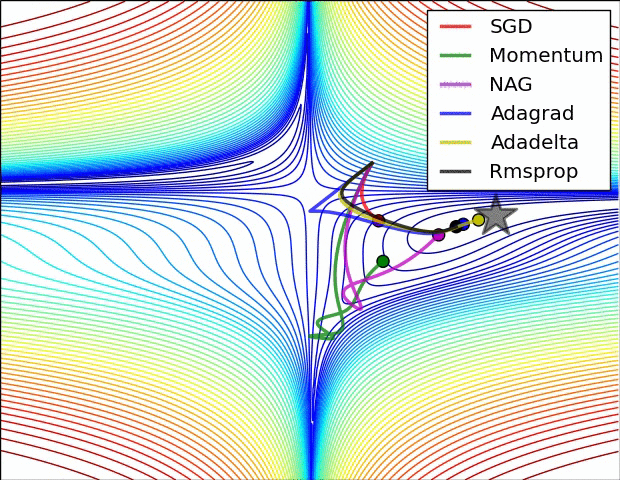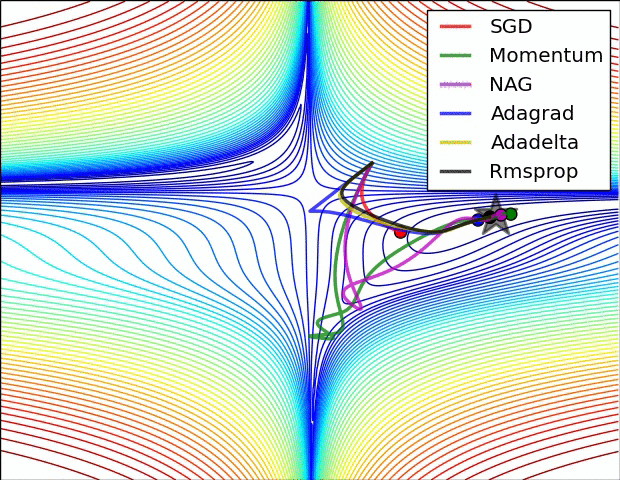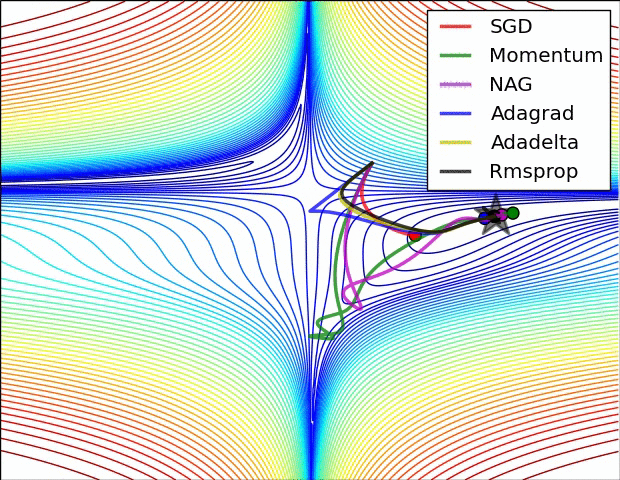
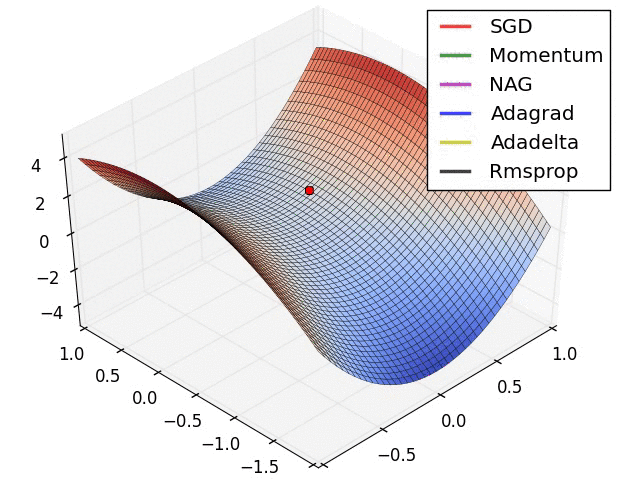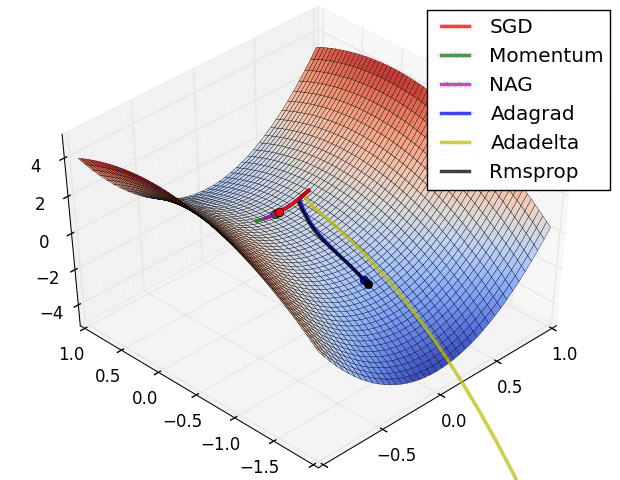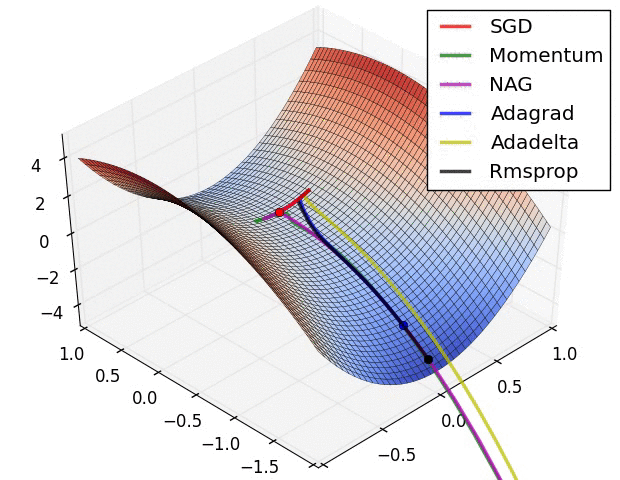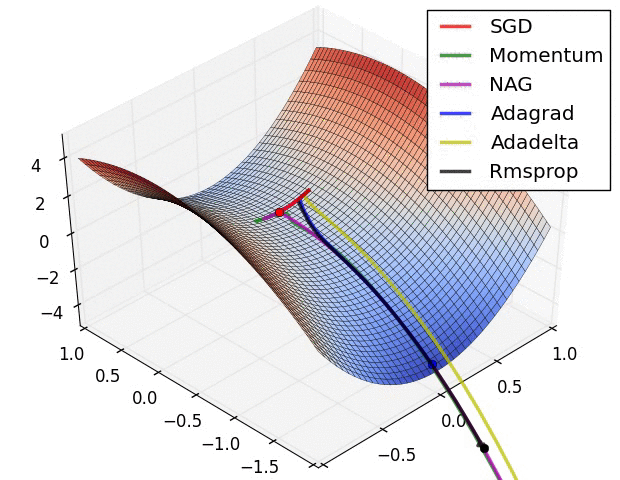
Gradient descent
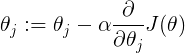
 = learning rate
= learning rate- Batch Gradient Descent:Each step of gradient descent uses all the training examples.
- Stochastic gradient descent(SGD):Use one example in each iteration
- Mini-batch Gradient descent:Use some examples in each iteration
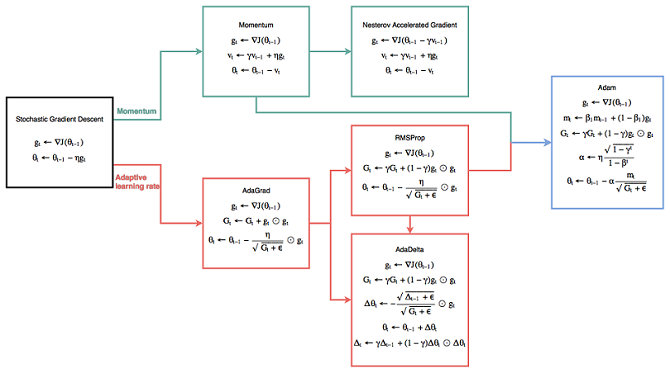
- Momentum:
Momentum is a method that helps accelerate SGD in the relevant direction and dampens oscillations. - AdaGrad:
Adagrad is an algorithm for gradient-based optimization that does just this: It adapts the learning rate to the parameters, performing larger updates for infrequent and smaller updates for frequent parameters. For this reason, it is well-suited for dealing with sparse data. - Adam:
Adaptive Moment Estimation (Adam) is another method that computes adaptive learning rates for each parameter. In addition to storing an exponentially decaying average of past squared gradients vt like Adadelta and RMSprop, Adam also keeps an exponentially decaying average of past gradients mt, similar to momentum.